Introduction
EmpowerID is a comprehensive identity management platform designed to offer flexible deployment options to cater to a wide range of organizational needs. Designed with adaptability in mind, EmpowerID supports deployment in SaaS, private cloud, on-premise, and classic server-based environments, ensuring that the software can fit seamlessly into different IT infrastructures.
The architecture is built to maintain consistency across these deployment models, meaning the core code base and system functionalities remain intact, regardless of how the platform is installed. This ensures uniformity in operations, facilitating a smoother user experience and easier management.
In the following sections, we will explore the various deployment options and delve into the specific architectural components of EmpowerID, including its use of Kubernetes clusters, worker and UI service containers, and integration with existing systems through a robust connector framework. This overview is intended to provide a clear understanding of how EmpowerID can enhance identity management in diverse IT environments while maintaining security and efficiency.
Deployment Options
EmpowerID offers a range of deployment options, ensuring it meets the diverse needs of organizations while maintaining consistent core functionality. Regardless of the deployment option, the code base and database are the same. There is no difference in the features or capabilities of EmpowerID, regardless of the deployment environment.
SaaS Deployment
The SaaS deployment allows companies to leverage EmpowerID without the need for installing additional infrastructure, apart from a cloud gateway and an optional API gateway. EmpowerID manages the SaaS instance on a cloud tenant, which simplifies management and ensures high availability. This option is particularly appealing to organizations wishing to reduce administrative overhead and focus on scalability and accessibility across different regions.
Private Cloud
Alternatively, EmpowerID can be installed in a private cloud, giving organizations enhanced control over their environment and data. This setup allows the management of the system to be handled internally by the customer or externally by EmpowerID as a managed service provider, offering flexibility and tailored configurations to meet specific business needs.
On-Premise, Containerized
For those requiring an on-premise solution, EmpowerID provides an option to run Docker containers in Kubernetes or Docker Swarm environments on customer hardware. This method is ideal for organizations seeking full control over their systems and the ability to meet stringent compliance requirements by maintaining data within internal firewalls.
On-Premise, Classic Server-Based
Lastly, the classic server-based installation is available for organizations preferring a more traditional approach. This involves deploying EmpowerID on existing server infrastructures, leveraging familiar resources and simplifying integration with legacy systems.
Each deployment path is crafted to align with strategic goals and operational needs, ensuring EmpowerID can be effectively utilized within any IT framework.
Reference Architectures
EmpowerID’s architecture supports both cloud-based and on-premise environments, each designed to optimize performance and scalability.
Cloud-Based Infrastructure
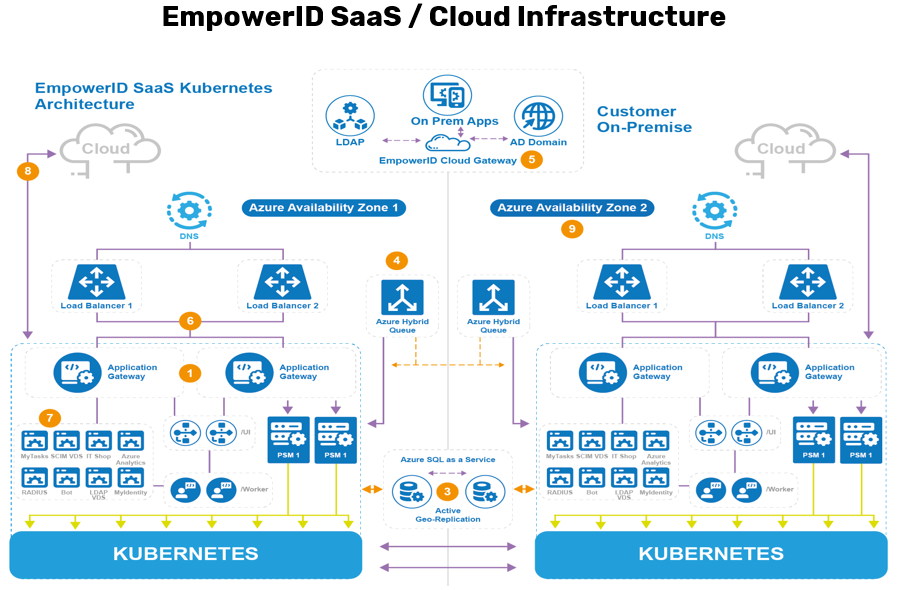
In a cloud-based setup, whether provided as a SaaS environment on the EmpowerID tenant or as a private cloud environment on the customer's tenant, EmpowerID utilizes Kubernetes clusters to host its components. This approach centralizes the deployment of EmpowerID's various systems and service containers. Within this cluster, worker containers handle backend processes and long-running jobs, while UI service containers manage front-end interfaces. The architecture includes redundant application gateways to ensure uninterrupted service delivery, and if organizations use privileged access management (PAM) capabilities, PSM containers are employed to secure session management.
Cloud infrastructure also integrates with Azure Availability Zones for enhanced reliability. EmpowerID’s components are duplicated across multiple zones, utilizing Azure SQL as a service with active geo-replication for data synchronization and disaster recovery. Communication with on-premise systems is facilitated by the EmpowerID Cloud Gateway, which interacts with Azure’s Hybrid Queue or Broker services, ensuring seamless data exchange and secure, outbound-only connections with the on-premise infrastructure.
On-Premise Infrastructure
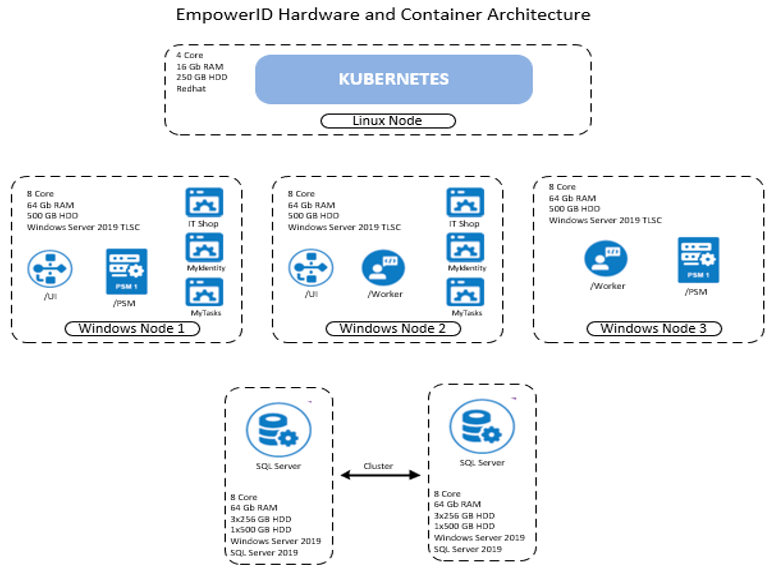
On-premise deployments are available in two options - Containerized or Server-based. The containerized deployment features a combination of Windows and Linux servers. Docker containers run on Windows nodes for consistent application management, while SQL servers operate in a clustered environment to ensure data redundancy and reliability. In this setup, Kubernetes clusters manage various microservices, UI containers, and worker containers, all coordinated through a Linux node responsible for cluster management. This architecture is aimed at providing full control over hardware and ensuring compliance with organizational policies.
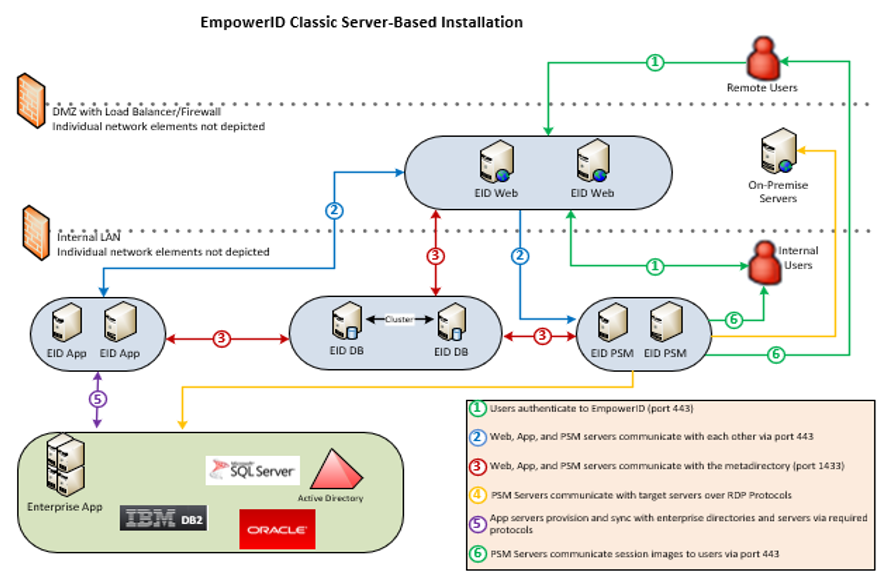
With the classic Server-based deployment the on-premise environment includes Windows services implemented on Windows servers for the processing and UI infrastructure. The back-end identity warehouse is housed on SQL servers which can be clustered and configured with Microsoft's "Always On" high availability features. This configuration supports organizations familiar with traditional server management and facilitates integration with existing systems.
The reference architectures offered by EmpowerID are robust, adaptable, and designed to meet various operational needs, ensuring performance and security are never compromised.
Key Components
EmpowerID's architecture comprises several crucial components designed to enhance the platform's functionality and efficiency. These elements are integral to processing, managing, and delivering robust identity management solutions.
Worker Containers
Worker containers, or servers are responsible for managing backend processes. They handle all long-running jobs and core application functionalities, ensuring that the system operates smoothly. These containers execute tasks such as application logic, job scheduling, and other essential operations that support the platform’s infrastructure.
UI Service Containers
The frontend of EmpowerID is managed by UI service containers or servers. These containers are crucial for handling user interfaces, delivering seamless access to applications, and ensuring a smooth user experience. The UI containers facilitate interactions between the user and the platform, supporting web-based interfaces and interactive activities.
Microservices and Application Gateways
EmpowerID employs a microservices architecture that allows for modular development and deployment of features. This design enables greater flexibility, scalability, and resilience within the system. Redundant application gateways are utilized to ensure that these services remain accessible and stable, even during infrastructure changes or failures.
These components work in unison to streamline processes, manage tasks effectively, and provide a robust platform for identity management. By maintaining a cohesive and integrated architecture, EmpowerID ensures an optimal balance of performance, scalability, and reliability across its deployments.
Server Roles and Server Jobs
EmpowerID’s architecture is designed for efficiency and resilience, utilizing server roles and server jobs as core components. These elements ensure the platform runs smoothly and adapts to varying workloads seamlessly.
Server Roles
Server roles in EmpowerID define the specific tasks that servers or containers perform within the ecosystem. This approach enhances both performance and manageability.
-
Frontend or UI Servers: These servers host processes supporting workflow interfaces and API endpoints, facilitating user interactions. They manage web UIs and serve as the primary access point for end users.
-
Backend or Application Servers: Handling complex, long-running security processes, data synchronization, and policy enforcement, these servers are designed primarily for application processing.
Server Jobs
Server jobs are granular tasks running asynchronously, ensuring efficient data and process handling by dividing operations into smaller, manageable tasks.
-
Job Processing: Server jobs deal with tasks like inventory updates and data provisioning. Each job accesses the database to determine which tasks need execution.
-
State-Driven Operation: Jobs operate based on the state of data, claiming records as they process them. This prevents multiple jobs from working on the same record simultaneously, maintaining data integrity.
-
Load Balancing and Failover: Multiple servers can handle the same jobs, supporting load balancing and failover. If one server goes offline, others continue processing without interruption.
-
Resilience and Continuity: Jobs can resume from where they left off in the event of a failure, ensuring robustness and reliability. This capability minimizes process disruptions and maintains continuity.
Together, server roles and server jobs form the backbone of EmpowerID’s architecture, allowing dynamic task management and maintaining high performance and stability. This design ensures EmpowerID effectively meets modern identity management demands.
EmpowerID Identity Process Architecture
The EmpowerID process architecture for managing identities and access is modular. It begins with source data from authoritative sources—what we call account stores. These are inventoried through our connector framework, which supports various protocols like REST APIs, SQL stored procedures, LDAP, SCIM, flat files, and universal database connections.
Once inventoried, the data is imported into EmpowerID as accounts. These accounts undergo an evaluation process to create managed person identities. This involves translating account data through an inbox process, resulting in fully managed identities.
Once managed identities are established, they can be assigned to business roles, locations, and management roles. This step leverages RBAC (Role-Based Access Control), ABAC (Attribute-Based Access Control), and PBAC (Policy-Based Access Control) to ensure dynamic, context-aware assignments.
Throughout an identity's lifecycle, EmpowerID continuously evaluates and updates access based on incoming data, ensuring roles and permissions remain accurate. Outbound jobs, such as provisioning policies, group membership reconciliations, and attribute synchronizations, propagate these assignments to target systems.
This entire process forms a loop, where target systems are regularly inventoried back into EmpowerID to ensure data consistency and closure.
Database and Storage
EmpowerID's robust database system is vital to its identity management capabilities. This expansive database contains all EmpowerID-specific objects and configuration data, and external system data inventories.
-
Structure: This expansive warehouse comprises over 1,200 tables, over 700 constructed views, and more than 20,000 stored procedures. These components are crucial for the processing, querying, and storage of data, providing an organized and efficient data management system.
-
Functionality: The warehouse inventories data from various systems such as SAP, Active Directory, and others. When data is connected and brought into the system, it is processed and aggregated here, streamlining management and accessibility across the platform.
Data Processing and Updates
EmpowerID ensures data consistency and integrity across its systems through a comprehensive process:
-
Connector Frameworks: Data from external systems is brought into the warehouse on a continuous and scheduled basis using various protocols like REST, LDAP, and others. As data is processed, the warehouse continuously updates, reconciles, and synchronizes the data between the external data source and the data in the database providing seamless integration and synchronization.
-
State Management: Data processing involves claiming records, updating target systems through connectors, and reinventorying systems to ensure synchronization. This approach maintains data accuracy and ensures changes are consistently reflected across all connected systems.
Overall, the database and storage architecture of EmpowerID is designed to provide a reliable, scalable, and comprehensive platform for managing identity data. This design underpins the platform's ability to meet the complex demands of modern identity management.
Permanent Workflows
Permanent workflows in EmpowerID are designed to run continuously, performing scheduled repetitive tasks on a consistent loop. These workflows are akin to server jobs but provide greater flexibility and ease of modification, allowing organizations to effectively manage ongoing processes without altering the underlying code.
Characteristics
-
Continuous Operation: Permanent workflows run continuously, ensuring that scheduled tasks are performed at regular intervals. This setup is crucial for maintaining up-to-date processes without manual intervention.
-
Singular Execution: Permanent workflows differ in another way with server jobs in that there can be only one instance of a permanent workflow active at a time across all servers. There is a Permanent Workflow server job that manages the initiation and recovery of permanent workflows that are enabled for processing.
Flexibility
-
Creation and Modification: Users can easily create, modify, and deploy permanent workflows through Workflow Studio. This flexibility allows organizations to adapt workflows as needed to meet changing business requirements.
-
Customization: Unlike server jobs, which are code-based, permanent workflows do not require code modification for updates, streamlining the customization process and reducing development time.
This approach of utilizing adaptable permanent workflows and resilient server jobs allows EmpowerID to support complex identity management needs, ensuring operational tasks are managed efficiently and adaptively, providing a robust, dependable framework for organizational processes.
EmpowerID Component Model
The EmpowerID component model forms the foundation of its system architecture, enabling an organized and modular approach to identity management. This model allows various elements of the platform to interact seamlessly, providing flexibility and efficiency.
Architecture and Structure
-
Components as Building Blocks: Each object within EmpowerID is treated as a component. These components have distinct properties and methods, which are executed as component methods. This structure allows for clear and organized data interaction.
-
SQL Views and Tables: The component model uses SQL tables and views to represent component objects and views, structured to facilitate easy access and comprehensive data management across the platform.
Functionality
-
Interactivity with API and UI: EmpowerID components are accessible via APIs, allowing developers to interact with stored data and execute processes programmatically. The UI also provides access to these components, making it intuitive for users to manage identities and processes.
-
Process Execution: All interactions within EmpowerID, whether through the UI or API, trigger specific component methods. This ensures that processes are executed efficiently and consistently.
Benefits
-
Modularity: The component model's design promotes a modular architecture, allowing individual elements to be developed, deployed, and updated independently.
-
Scalability and Efficiency: The organized approach to managing components ensures that processes scale efficiently and maintain high performance, even as organizational needs evolve.
EmpowerID's component model is central to its ability to provide a flexible, scalable, and efficient identity management solution, allowing organizations to tailor the platform to their specific needs while ensuring robustness and reliability.